
4차 프로젝트가 끝났다. 4차 프로젝트는 배민 문방구를 클론 해보는 프로젝트였는데 기획, 디자인 같은것들은 없어서 모두 여기저기 쇼핑몰을 참고 하면서 진행했었다. 또 다른 프로젝트에 비해 기간이 1주 더 길게 주어져서 총 3주로 진행했으며, 팀원도 4명이어서 조금 안정적이게 프로젝트를 진행할 수 있었다.
이번 프로젝트도 이전 프로젝트와 같이 키워드 위주로 작성후 마지막에 협업은 어땠는지 회고 하려고 한다.
키워드 :
셋팅 관련 : storybook, Git [Discussion, Action, Project]
기술 관련 : typescript, react, recoil, react query, styled-component
서버 및 백엔드 : AWS EC2, ELK stack

1. 시작
팀원 :
마지막 프로젝트까지 오게되면 대부분의 사람들과는 아이스 브레이킹이되어 빠르게 팀원과 친해질 수 있었다. 또 팀원분들 성격이 다들 양보하는 모습이 있고 좋다 보니 커뮤니케이션 과정에서 취향차이에 대한 부분은 문제가 발생하지는 않았다.
프로젝트 :
이번 프로젝트에서는 드디어 리액트를 사용하게 되었는데 조건사항이 많았다. 큰 요구사항들을 살펴보면
1. CRA 사용금지
2. 리액트 라우터 사용금지 (자체적으로 개발하여 사용하기).
3. 단위 테스트. UI 컴포넌트, 상태변경 컴포넌트에 대해서 단위 테스트를 한다.
4. CSS-in-JS 형태의 스타일 작성 (styled-component를 사용하지만 2주차 부터는 자체적으로 개발)
5. 자동배포
6. (선택) 첫 페이지는 서버사이드 렌더링 방식을 시도해서, 서버단에서 렌더링한 결과를 보내준다.
위의 요구사항중 [6, 4, 3]의 요구사항은 제대로 하지 못하였다... 어려운 점이 꽤나 많이 있었는데 뒤에서 차츰차츰 이야기를 할 예정이다.
2. 프로젝트 중 겪었던 문제
1. 첫 페이지 서버사이드 렌더링 방식 시도
- 아 이거 진짜 삽질을 많이 했다. 거진 2일정도를 이 부분에 힘을 썼으니..;;;; 결과부터 이야기하면 구현에는 실패했다. Next.js를 쓰면 되지만 Next.js를 사용하면 안되는 줄로 알고 있었다. 팀원 중 한분이 여기에 많이 힘을 쓰셨었는데 동작하는데 어려움이 많았다. 실제 각 페이지 url경로로 접근했을 때 페이지 내용을 가져와 지는것 까지 동작하긴 했었으나 스타일 컴포넌트등 빌드를 해야하는여럿 문제들이 있어 시간을 너무 많이 소비한 것 같아 빠르게 포기한 내용이 었다. 어떻게 진행 했나 하면 크게
1. nginx 웹서버가 따로 있고, 프론트 serverSide 렌더링을 위한 express 서버를 따로 만들었다.
2. nginx로 요청이들어오면 express로 요청을 서빙한다.
3. 서빙된 요청에 대해 렌더링하여 보내준다.
순서에 대한 내용은 엄청 가볍게 다루어지고 있지만 스타일컴포넌트 등 빌드를 해야하는 문제들이 나타나면서 복잡해졌다.. 나중에 남는 시간에 진행하여 넣어줘야지 라는 생각을 하지 못한게 ssr로 구현하게 된다면 일반적으로 리액트 프론트 구조를 짜는것과는 다르게 짜야 될것 같은 생각이 강하게 들었고 결국 처음에 시도해서 안되면 아예 포기하자라는 의견으로 통일이 되었다. 그래도 ssr을 완벽하진 않더라도 렌더링이 된 화면을 받아왔다는 것 자체에서 끝내고 ssr에 대해서는 거의 손대지 않았다.. 나중에라도 한번 다루어 보고 싶은 내용이다.
2. CSS-in-JS 형태의 스타일 작성 (styled-component를 사용하지만 2주차 부터는 자체적으로 개발)
- 이부분도 서버사이드 렌더링에 많이 힘쓰신 팀원이 진행 하였으나.... 이미 styled-component를 우리 팀에서 너무 잘 쓰고 있어서 문제가 있었다. 단순 컴포넌트에 css를 적용하는 것은 되었으나 문제는 컴포넌트 스타일안에서 컴포넌트를 새롭게 불러 css를 덮어씌우거나 변경하는 부분, styled(Component) 형태로 적용하는 부분 등... 깊게 사용하면 할수록 구현하는데 많은 어려움이 있었고 결국 이 부분도 커스텀으로 만들어 기본 컴포넌트에 스타일을 적용할 수 있게 만들었으나 기존에 사용한 스타일컴포넌트들 대체해서 사용하기에는 무리가 많이 있었다... 결국 이 부분도 프로젝트에서 미완성으로 끝내게된 부분이다.
3. 테스트를 위한 도구 ( Cromatic, StroyBook)
- 이 부분도 다른팀원이 주로 셋팅과 적용을 진행했었고 아주 많은 시행착오가 있었다. fork한 레포지토리에서 pull request를 할때 repository의 secret_key에 접근할 수 없다는 것이 원인이 되어 삽질을 좀 많이 했었고 내가 스토리북에서 삽질한 부분은 스토리북 ui테스트를 할때 api 요청이 잘 안되는 것이 원인이 었다. 크로마틱으로 배포된 페이지에서 api 요청을 통한 ui테스트가 안되었었고 원인을 찾지 못하여 엄청난 삽질을 했다. MSW를 설치하여 추가해보기도 하고, server api 호출 url을 변경하여 테스트도 해보았다. 웃긴건 localhost로 api요청 서버를 켜서 크로마틱에서 localhost로 요청을 보내면 잘 동작하는 것이었다. 중간중간 짬나는 시간에 확인했으나 안되가지고 팀원에게 상황을 공유하고 다른 부분을 했으나 마음이 너무 찝찝하여 남는 시간에 계속 왜안되지 왜안되지 하며 생각했었다.
그러다가 아침에 자고 눈을 떳는데 아 http !!라는 게 그냥 떠올랐고 확인했을 때 https에서 http api 응답을 가져오는 것이 안된다는 것을 알았다. 여기서 든 의문점은 MSW를 이용한 것은 왜 동작을 하지 않았나 하는 부분이 의문점으로 들었고 찾아본 결과 MSW와 크로마틱은 연동이 잘 안된다는 이슈가 있었고 MSW는 포기했다. 일단 문제의 원인을 찾았으니 http 서버를 https로 올려야 했다.
다만 여기서의 문제는 이걸 마무리하기 하루전에 알았다는 점이 문제였다..;; 결국 포기하고 안되는 원인을 파악했다는 부분에서 그쳤다.
4. React Query ( 인피니티 스크롤 )
- 리액트 쿼리에서 인피니티 스크롤을 구현하기 위해서 좋은 기능이 있다 바로 infinity query라는 놈인데 데이터를 페이지 단위로 끊어서 호출하고 받아올수 있다는 장점이 있다. 리액트 쿼리의 장점과 결합하여 데이터를 캐싱까지 해주어 매번 새로운 호출을 안해줘도 되고 장점이 많았다. Intersection Observer를 이용하여 다음페이지 쿼리를 계속 호출하게 하여 구현을 하였다.
다만 첫번째 문제는 인피니티 쿼리에 대해 존재를 '이제 이거가지고 인피니티 스크롤 만들어야지 ~' 할 때 알았다. 이게 왜 그렇냐면 인피니티 쿼리에서 데이터를 받아올 때에는 page, totaldata 같은 정보를 서버에서 같이 보내줘야 했고 이 부분이 infinite query의 next page를 호출할때 사용하는 argument가 되었다. 즉 이 부분을 고려하고 코드를 짠 것이 아니어서 이에 맞춰 수정하기에는 기존에 이 api를 사용하던 부분을 모두 수정해주어야 했고 작업이 많은 과정이었기에 고민을 많이 하였다. 1차적으로는 다행이 클라이언트에서 argument를 추가할 수있는 것을 찾을 수 있었고 받아올 데이터 개수를 상태값으로 추가하여 다음페이지 데이터를 새롭게 요청할 수 있도록 하였다.
두번째 문제로는 이게 전체 데이터수, 전체 페이지 같은 정보를 가지고 있는 것이 아니다보니 인피니티 스크롤을 내릴경우 계속해서 요청되는 현상이 발생하였다. 여기서 api를 수정하는 수밖에 없는건가...? 라는 생각을 했으나 다행이 아이디어가 번뜩여 가장 최근 데이터를 가져왔을 때 기존 스크롤 했을때 가져오는 데이터의 갯수 보다 미만일경우 다음 요청을 하지 않도록 수정하였고 이렇게 하여 최대 1번의 추가 요청을 하는 인피니티 스크롤을 완성 할 수 있었다.
5. 엘라스틱 서치
- 엘라스틱 서치를 적용하는데 있어 자동완성이 가장 큰 문제였다. 엘라스틱은 기본적으로 검색할 문자 또는 문장을 토큰화 하여 인덱싱을 하는데 예를 들어 '피자가 먹고싶다' 라는 것이 있으면 토큰화 하는 기준에 따라 '피자, 피자가, 먹고, 먹고싶다' 같이 분리하여 정보를 가지고 있는다. 이후에 검색시 위 인덱싱에 해당되는 데이터들을 가져오는 것인데 문제점은 '핒, 피ㅈ'와 같이 초성이 겹쳐있거나 초성검색은 안된다는 문제점이 있다. 또한 최소 글자를 2글자로 토큰화 하면 '피'로 검색할 경우 나타나지 않는다. 이 당시 문제점을 파악하고 초성 검색을 할 수 있게 토큰화 하는 플러그인을 찾았었는데 버전문제 때문에 적용이 안되었었고.. 이를 수정하기 위해서는 자바를 어느정도 다룰 수 있어야 했다. 문제는 내가 자바를 진짜 못한다는 것이었고 이를 위해서 투자할 가치가 있는가? 라는 의문점과 함께 팀원에게 상황을 공유했고 팀원은 엘라스틱 서치가 초성검색, '핒, 피ㅈ'와 같은 검색을 제외 하고는 잘 동작한다는 점에서 충분하다는 의견이었다. 덧 붙여서 이미 많은 시간을 소모했기에 문제점이 무엇이고 해결 방안에 대해 고민하고 방안까지 제시를 할수 있다는 점에 충분하다고 이야기 하였다. 나 또한 비슷한 생각이었고 아직 추가하고 적용할 내용이 많기에 엘라스틱서치는 여기서 마무리를 하였다.
3. 프로젝트 중 적용한 내용
1. ELK Stack
- 자동완성 검색과 빠른 검색속도를 위해서 추가하였다. 엘라스틱을 설치하여 Mysql 데이터를 복사하여 넣었었고 edge_ngram이라는 엘라스틱에 기본 내장되어있는 토크나이저를 이용하여 데이터를 토큰화 했고 이를 이용하여 검색 할 수 있게 하였다. 설치하고 적용한 과정은 다음과 같다
1. 엘라스틱, 키바나, 로그스태시, 파일비츠 설치
2. 키바나를 이용하여 엘라스틱 인덱스 추가 (인텍스는 테이블과 비슷한 개념이라고 생각된다.)
- 키바나는 엘라스틱을 gui 형태로 보게 해줄 수 있는 웹툴이다.
3. 로그 스태시를 이용하여 mysql데이터를 elastic search에 연동
4. 로그 스태시에 크론탭과 동일한 설정이 있는데 이를 이용하여 주기적으로 데이터를 받아올 수 있게 설정
2. 자동배포
- 자동배포 관련해서는 깊게 관여하지 않아가지구 팀원이 작성한 글로 대체 합니다.
[자동배포 관련 워크플로우 설명, ec2 용량이 왜이렇게 많이 차지하지 ?]
3. React 상태관리
- 이번 프로젝트에서 상태관리는 총 7가지를 찾아보고 고민하였다. ContextAPI, Redux, Mobx, Recoil, React Query, useSWR, Zustand 사실상 찾아보고 특성에 대한 내용만 정리하고 팀과 의견을 나누었다. 맨 처음 고민한 것은 이번 프로젝트에서 상태에 대해 어떠한 정의를 내릴 것인가에 대한 고민이었다. 여러 의견을 나누다 결정한 것이 바로 서버에서 받아오는 값, 여러개의 컴포넌트에서 사용하는값, 전체 컴폰넌트에서 사용하는 값으로 총 3개로 나누기로 하였다. 그래서 각각에 맞는 상태 라이브러리를 사용하기로 했고 이런 팀과의 의견공유를 통해 프로젝트당 상태라이브러리는 하나만 !! 이라는 무의식적인 생각이 사라졌다. 오히려 왜 이런 생각을 가지고 있었을까라는 의문이 들정도였다.
각 상태관리 라이브러리에 대해 짧게 이야기하면 다음과 같다.
---- 전역 상태를 위한 상태라이브러리
Redux - 사용하기위해 작성할 코드들이 길어진다. redux-saga, thunk 같은 것들이 있지만 결국 redux와 연관지어야하며 러닝커브가 높은편이다.
MobX - 옵저버 패턴을 이용한다는 점과 러닝커브가 리덕스에 비해 많이 낮다는 장점이 있다. 다만 MobX는 클래스형 컴포넌트를 위한 상태 라이브러리다. 함수형 컴포넌트를 위한 mobx-react 가 있으나 결국 추가적으로 라이브러리를 받아야 한다는 것도 불편하게 다가왔다.
Recoil - 러닝커브가 매우 낮고 페이스북 재직자가 만들어 리액트 hook과 굉장히 잘 맞는다. 데이터 캐싱도 지원해주기 때문에 캐싱용도로도 사용할 수 있다. 내가 생각한 리코일의 단점은 버전이 낮아 라이브러리 신뢰성이 낮은 편이다. 실 프로젝트에서 적용하기는 조금 어렵다라는 의견이 많다. (그럼에도 toss 프론트 팀은 쓰고 있더라. 이 부분에서 써도 좋을 것 같다는 생각이 많이들었다.)
Zustand - 짧게 이야기 하면 미니멀한 Redux이다. 리덕스가 제공하는 기능을 거의 대부분 비슷하게 제공하면서, 더 간단하다! 자연스럽게 로직이 명확해지고, 쓸 데 없는 코드들이 없어진다! 다만 리덕스와 비슷해서 제외를 하였다.
---- 비동기 로직을 위한 상태라이브러리
React Query - 비동기 로직을 다루기 위한 라이브러리로 loading, error 처리 등을 쉽게 구현이 가능하다.
useSWR - NEXT.js를 만든 회사에서 만들었다. 리액트 쿼리를 선택한 가장 큰이유이다. useSWR은 next.js에서 더욱 매끄럽게 잘 동작한다는 의견이 있어 공감이 바로 되어 react query로 확정지었다.
결정된 상태관리로는 theme과 같은 모든 컴포넌트에서 사용되는 상태값은 contextAPI로 관리하기로 했고, 몇몇의 컴포넌트에서 사용될수 있는 상태의 경우 Recoil을 사용하기로 결정 하였으며, API서버에서 받아오는 데이터는 React Query를 이용해서 관리하기로 하였다. 상태관리에 대해서는 정말 많은 고민이 필요한것 같다. 상태관리 라이브러리에 관해 충분히 고민하여서 도출된 결과인가?? 라고 하면 충분히 고민하였다고 말하기는 어려운 수준이지만 그래도 나름 상태에대해 정의를 내리고 그에 맞는 상태라이브러리를 찾아 팀원과 고민을 했다는 점이 크게 다가왔다.
4. Type ORM
- 이전 프로젝트에서 시퀄라이저를 사용했는데 이번에는 타입orm을 써보고싶어 팀원에게 이야기하여 적용하였다. 사실 백엔트 초기 설정관련해서는 거의 내가 하여 typeorm으로 설정을 모두 마쳤다. (sequlize-typescipt가 typeorm과 비슷한 점 있는데 이전에는 단순 sequlize만 사용해서 이를 비교한다. )이에 대해서 시퀄라이저와 비교했을 때의 장점은 몇가지 있는데 다음과 같다.
1. 러닝커브가 시퀄라이저에 비해 낮다. 시퀄라이저를 먼저 해보고 다뤄서 그런지 비교적 빠르게 적응 하고 코드를 작성할 수 있었다.
2. "@"데코레이터를 이용하여 좀더 직관적인 테이블 구성을 할 수 있다.
3. 테이블 1:m M:1 연결이 굉장히 쉽다. 시퀄라이저에서는 테이블 모델들을 따로 불러서 연결해줬어야 했는데 typeorm에서는 모델 내부에서 쉽게 연결이 가능하다는점
typeorm으로 db테이블을 구현하는데 있어서 굉장히 쉽게 되었고 나에게는 좋게 다가왔다. ( 그래도 일반 쿼리가.... )
5. Story Book
- 테스팅 도구로 채택하였다. 원래는 기존 jest를 이용하여 작성하려했으나 프론트 단에서 테스트를 해야하는 것은 거진 ui뿐이라고 팀에서 의견이 나왔고 실제 테스트는 ui가 어떻게 변경되었는지 빠르게 확인 할수 있는 스토리북을 선택하였다. 적용하는데 어려움이 있었지만 많이 신선했고 디자이너와 협업을 할때에는 굉장히 좋은 도구라고 생각된다. 단점은 api에 관련한 테스트가 조금 어려웠고, 개발자간에 리뷰를 하게되면 code, ui 리뷰를 같이 해야하는 리뷰 x2 !!와 종종 생기는 상태에 관한 스토리북 이슈들이 많이 생겼다. react-query 값을 적용하는데 있어서 문제가 생겨 단순 mock 데이터를 이용하여 보여주는 수밖에 없었다. 추가적인 문제로는 pull request를 할때마다 gif의 경우는 계속해서 바뀌었다는 표시를 보여주었다. 불필요한 내용들이 ui테스팅에 추가되다보니 완벽하게 적용했다고는 어려운 것 같다.
그럼에도 이전 ui와 비교하여 다른점을 보여준다거나 바로바로 ui를 테스팅할 수 있다는 점, 배포된 상태이기 때문에 어디서든지 확인 할 수 있다는 점이 이점으로 작용되어 적용할 수 있었다.
6. 크롤링
- 프로젝트에서 카테고리 탭에서 대각선 이동에는 탭이 변하지 않도록 구현하는 부분이 있었는데 문제는 배민문방구에 카테고리가 너무 적게 있다는 것이 문제였다. 그래서 새롭게 데이터를 크롤링해와서 많은 카테고리를 추가하고나서 구현하려고했고, 이 크롤링의 데이터는 쿠팡에서 가져오기로 했다. 쿠팡의 문구 카테고리의 데이터를 각 카테고리별 60개씩 데이터를 크롤링 하기로 했고 javascript으로 구현하기에는 크롤링 시간이 너무 오래걸릴 것 같아서 go라는 언어를 이용하여 크롤링을 하였다. 기존에 해본 경험도 있고 go routin의 강점을 알고 있었기에 주말동안 구현하여 데이터를 크롤링 해왔다. 5분정도의 시간으로 약 7200가 조금 넘는 데이터를 크롤링 할 수 있었고 상품의 상세 내용도 api 호출을 해야 했기 때문에 실제 페이지 호출 횟수는 16000회 정도 된 것 같다. 만약 자바스크립트나 파이썬으로 멀티쓰레드 없이 구현했다면 크롤링에도 엄청 많은 시간 소요가 되었을 것이고 이러한 부분은 매우 잘 적용했다고 생각한다. ( 더 빠르게 할 수 있었는데 초당 페이지 요청 횟수가 제한되어있었는지 제대로 값을 못가져오는 현상이 있었다...)
7. Git [Discussion, Action, Project]
- 이 번 프로젝트에서는 깃을 기똥차게 사용한 것으로 생각된다. Discussion이라는 탭을 이용하여 주요 안건사항들을 올려 슬랙과의 별개로 다룰 수 있게 하였고 (이 것은 주요 내용을 빠르게 확인 할 수 있다는 장점이 있다.), github action을 사용하여 [client, server, chromatic] 으로 나누어 자동배포를 구현하였다. 또 Project 탭을 이용하여 단순히 이 프로젝트 전체가 아닌 크게 페이지 단위로 나누어 이슈를 부분부분 연결하고 진행도를 쉽게 파악하여 일을 정리 하는 장점이 있었다. 아마 다음 프로젝트에서도 깃 프로젝트 디스커션을 잘 이용할 수 있을 것 같다. 각탭 별로 다음 이미지와 같이 사용하였다.


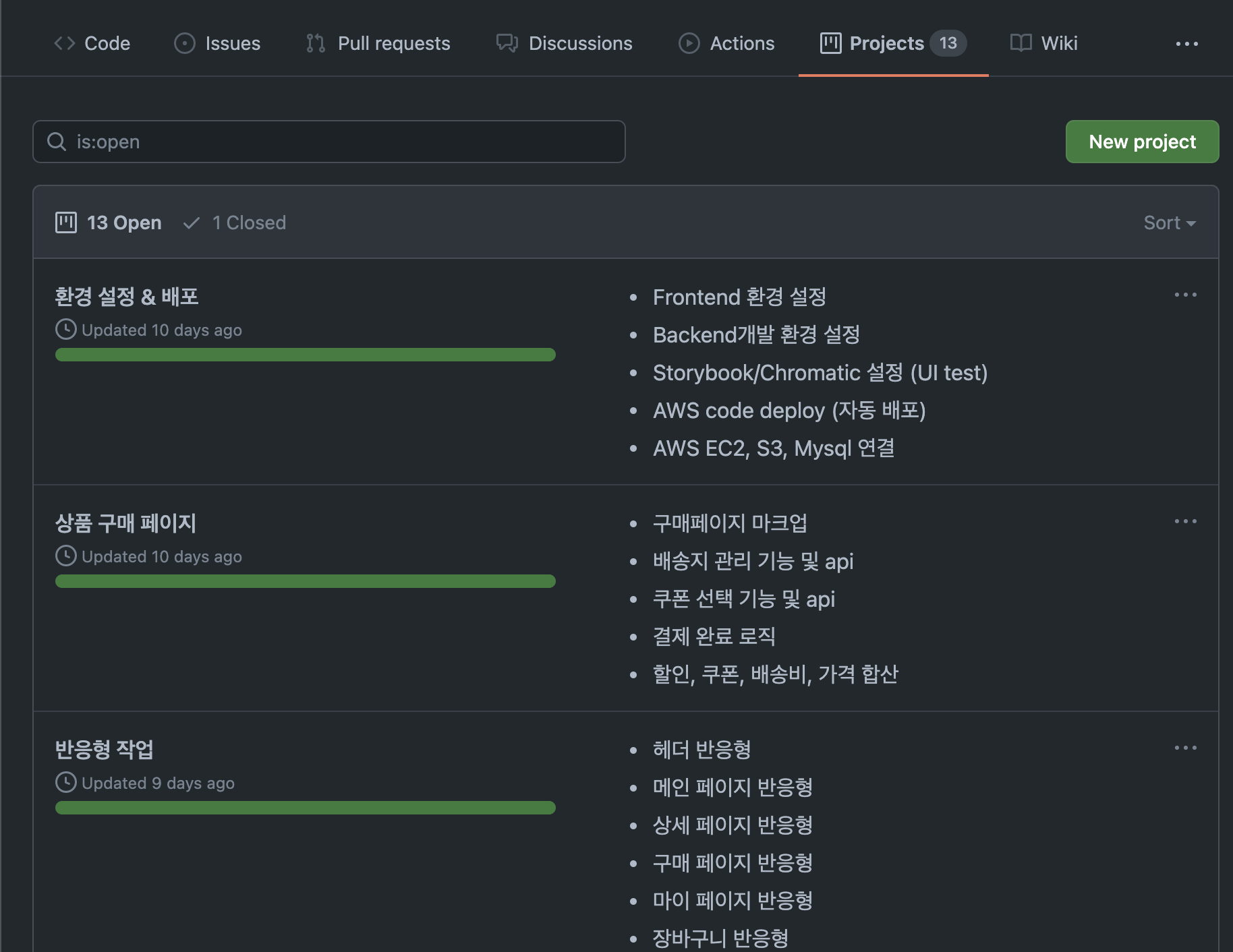
4. 협력
우선 협력에서는 가장 원활하고 잘되었던 프로젝트였다. 필요한 부분에서는 대부분 모두 공유하고 의견을 나누었고 어려운 부분은 무조건 팀원과 공유하여 해결 하였다. 이렇게 할 수 있었음에는 인원수가 4명이어서인 것도 몫을 하는것 같고 정말 협업툴을 잘 사용했다는 점이 있는 것 같다.
우선적으로 github discussion과 project를 만큼은 정말 알차게 사용하였다. 어떤 내용을 다루었고 진행사항이 어떻게 되고 있는지 바로 바로 확인 할 수 있다는 점이 가장 컸다.
slack에서는 잡담 + 간단한 의견 및 필요 내용 공유 등을 진행하였고 회의가 필요한 내용이다 싶으면 gather로 모여서 회의하였다.
gather에서는 주로 회의 관련하여 진행하였다. slack에서 큰 이슈나, 오전 스크럼등은 gather에서 모여 화상공유를 통해 내용을 다루기도 하였다. 물론 이렇게 진행하는 것이 당연하겠지만 인원수가 4명이다 보니 이전 보다 좀더 크게 다가왔다.
github 사용에 대해서 만큼은 정말 기똥차게 배워갔다.
5. 최종회고
이번 프로젝트는 우선 협력이 가장 잘된 케이스였다. 다만 아쉬운 점은 이번 프로젝트에서 내가 작업했던 부분은 크롤링, 백엔드 셋팅, 엘라스틱서치 적용을 주로 하였고 프론트 작업으로는 헤더, 카테고리페이지를 중심으로 작업을 해서 프론트 작업이 다른 팀원에 비해 적은 편이었다. 빠르게 작업을 마치고 프론트 작업을 했었어야 했는데...
총 4번의 프로젝트를 하고 나서 협업능력과 기술적 능력은 정말 엄청 성장한게 느껴진다. 나름 시간을 어느정도 잡고 작업을 진행 할수 있게 되었다. 물론 계획한대로 진행되는 경우는 많지는 않았지만 그 오차가 점점 줄어드는 것이 보인다.
아쉬운 것은 개발자간의 협력만 있었던 점이 많이 아쉬웠다. 사실상 백엔드도 했으니 프론트 백엔드의 협력도 아니었고, 디자이너와의 협력도 없었던점, 더 나아간다면 기획자와의 협력도 있을 수 있을 것같다. 다양한 분야의 사람들과 협업을 하지 못했던점이 가장 큰 아쉬움으로 남았고 이런 아쉬움이 있어 새로운 협업을 찾기위해 디프만이라는 곳을 지원하여 현재 디프만 10기로 활동하려고 한다 !! 새로운 협업의 장으로 떠날 시간이다.
그동안 우테캠 하느라 고생 많았다 :)
참고내용
[1] Infinity Query (React Query)
[2] 자동배포 관련 워크플로우 설명
[4] React 상태관리
Comment